
IBM Cloud Pak for Integration – Resource Configuration
This blog post aims to help you consider configuration of your Cloud Pak for Integration (CP4I) instance resources to achieve zero/minimal downtime and minimise unexpected bottlenecks in a Kubernetes/Openshift environment. The focus is on the configurable container resources that you can define in the CP4I Helm charts and how they can impact availability and performance when the Kubernetes node is under resource pressure.
We discuss the two compute resources CPU and Memory.
KUBERNETES RESOURCE CLASSIFICATION
The above two compute resources (CPU and Memory) are classified differently in Kubernetes. Due to their classification, the outcome when the Kubernetes node comes under resource pressure is very different.

QUALITY OF SERVICE FOR PODS
In Kubernetes, each pod is assigned a quality of service (QoS) level based on their CPU and memory resource specification. Kubernetes uses QoS classes to make decisions about scheduling and evicting pods. Just like any cattle in the cluster, each CP4I pod is assigned a QoS class.
The three QoS assigned to pods are detailed in the table below.

BEST EFFORT CONFIGURATION PARAMETERS

BURSTABLE CONFIGURATION PARAMETERS

GUARANTEED CONFIGURATION PARAMETERS

POD EVICTION POLICY
When a node is under memory resource pressure, the kubelet is responsible for ranking and evicting Pods.
The order of eviction is described below.
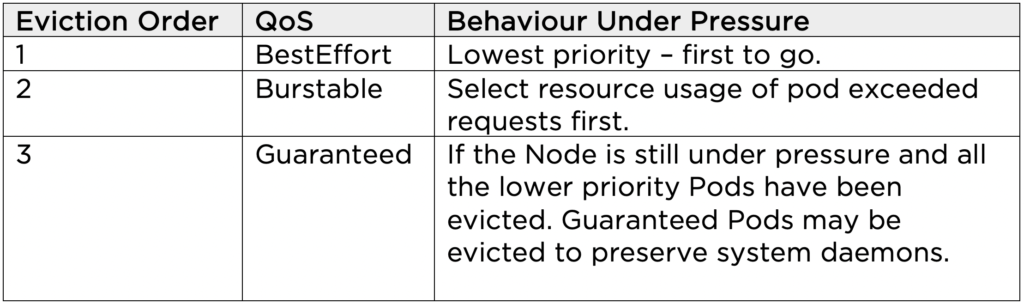
*Note: within each QoS category, the Pods are ordered by their Priority (a Pod property) during the eviction ranking process.
These evicted pods are scheduled in a different node if they are managed by a ReplicaSet – provided there are sufficient resources to accommodate the requests.
NODE OUT OF MEMORY (OOM)
In a situation when a node runs out of memory before the eviction policy can kick in, the OOM killer calculates and ranks Pods by its OOM score. The oom-score-adj value is one of the input parameters for the OOM score calculation. The adjustment value is based on the Pod’s QoS.

The oom killer evicts the Pod with the highest oom score. That score is derived from the percentage of memory it is using on the node in addition to the adjustment value. Based on the table above, the Pods with Best Effort QoS are likely to be killed first.
MONITORING AND ALERTING
Using the out of the box monitoring dashboards and alerting features in Openshift and CP4I, you can easily track and manage the pod resources before a node becomes stressed.
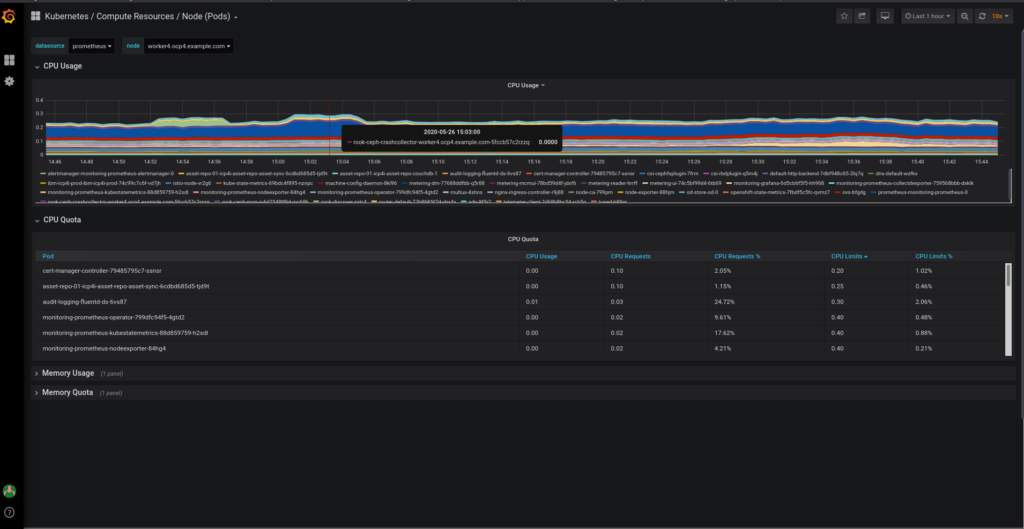
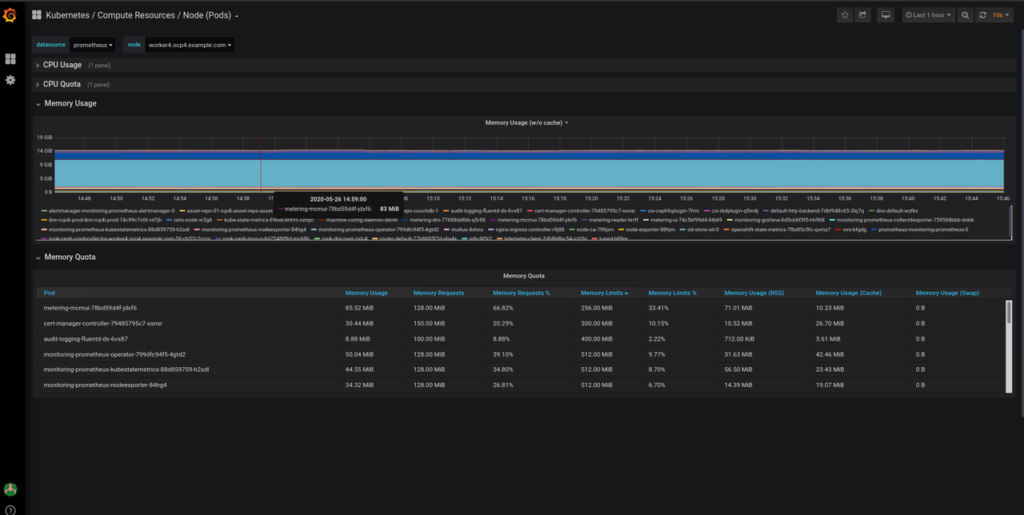
FROM OPENSHIFT
Leveraging the predefined Grafana dashboards and alerting capabilities in Prometheus to monitor each Kubernetes node.
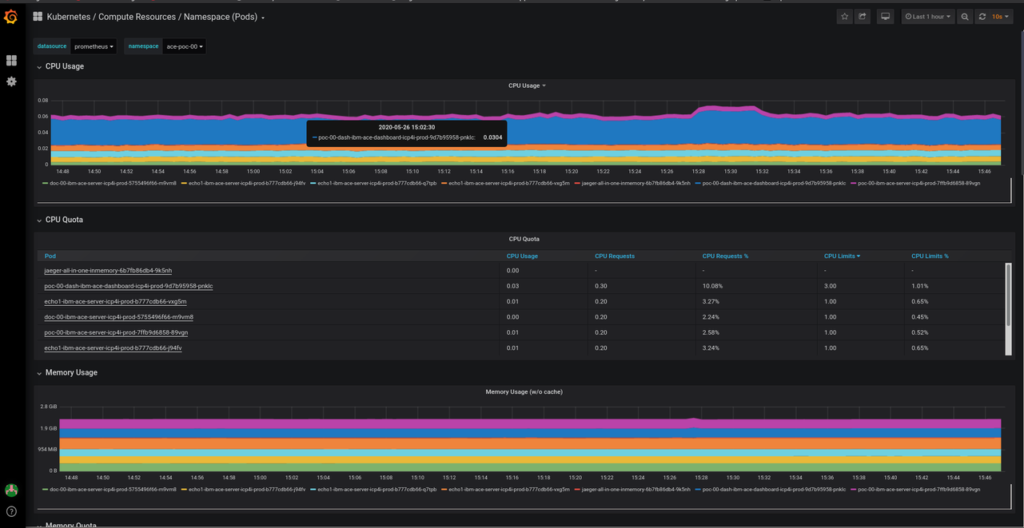
FROM CP4I MONITORING
Cloud Pak for Integration provides the same monitoring features as Openshift. Leveraging the same opensource-based Grafana dashboards we can watch the Pods and containers within an application namespace.
CP4I RECOMMENDATIONS
CP4I instances like ACE, MQ and APIC Pods are usually running mission-critical applications. The following considerations are highly recommended to avoid eviction even in a Multi-AZ/Multi-Node architecture to maintain the application’s SLA and/or QoS level.
- Determine the expected workload of the application Pod to work out its compute resource requirements early during the testing phase;
- Aim to configure the CP4I related helm charts with the same resource requests and limits values. Set the limits to a higher value if the application workload is bursty and compute resources are limited;
- Do not leave the resource definition undefined – CP4I helm charts have default values mitigating the risk;
- Deploy the CP4I application pod to at least 2 nodes;
- Set CPU Quota in the CP4I project namespace to prevent Kubernetes from overcommitting compressable CPU resources.
- Limit the number of Pods per node based on the expected workload.
- Understand each CP4I application Pod workload and resource usage profile before introducing or scaling an application in a cluster.
REFERENCES
- Kubernetes Documentation
- O’Reilly: Kubernetes patterns for designing cloud-native apps by Red Hat
- IBM Helm Charts